
人人好,我是 Ai 学习的老章
MiniMax M2.1 大模子文献终于来了
我看官方部署文档,天然模子文献唯一 230GB,然则若是念念要守旧更高高低文达到理念念遵守,所需显存已经蛮高的:模子权重 220GB+ 每百万 Tokons 高低文需要 240GB 显存。
以下为保举建立,实质需求请笔据业务场景调理:
• 96G x4 GPU:支握 40 万 token 的总高低文。
• 141G x8 GPU:支握长达 300 万 token 的总高低文。(官方文档原文写的 144GB,maybe 笔误)
部署剧本(需要 nightly 版块的 vllm):
uv venv
source .venv/bin/activate
uv pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly
SAFETENSORS_FAST_GPU=1 vllm serve \
MiniMaxAI/MiniMax-M2.1 --trust-remote-code \
--tensor-parallel-size 4 \
--enable-auto-tool-choice --tool-call-parser minimax_m2 \
--reasoning-parser minimax_m2_append_think
保举几个主流且肃穆的量化版吧,腹地跑起来本钱低好多
Unsloth
当先登场的是 大模子量化界翘楚:unsloth
从 1-bit 到 16-bit 皆有,llama.cpp 滥觞,过失是慢
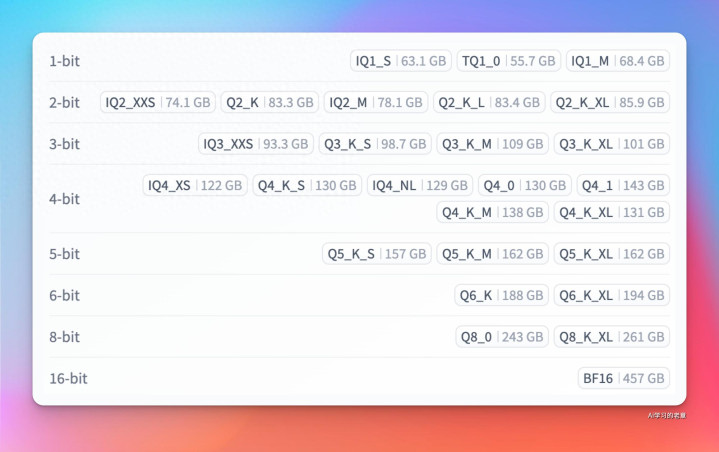
https://huggingface.co/unsloth/MiniMax-M2.1-GGUF
QuantTrio/MiniMax-M2.1-AWQ
GPU 用户 激烈保举这个,模子文献 125GB,不错 vLLM 启动,版块 0.13 即可
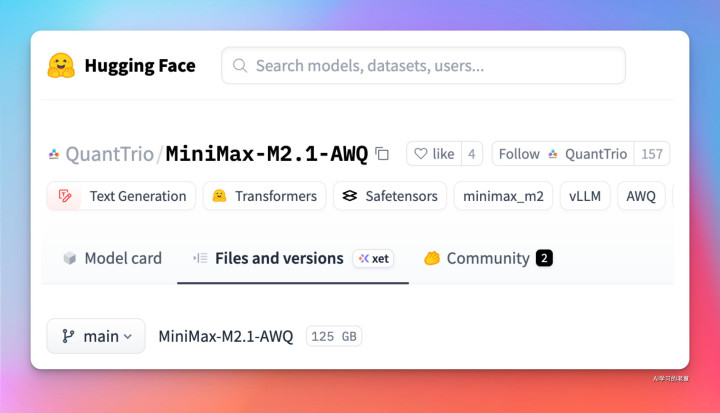
https://huggingface.co/QuantTrio/MiniMax-M2.1-AWQ
启动剧本:
export VLLM_USE_DEEP_GEMM=0
export VLLM_USE_FLASHINFER_MOE_FP16=1
export VLLM_USE_FLASHINFER_SAMPLER=0
export OMP_NUM_THREADS=4
vllm serve \
__YOUR_PATH__/QuantTrio/MiniMax-M2.1-AWQ \
--served-model-name MY_MODEL \
--swap-space 16 \
--max-num-seqs 32 \
--max-model-len 32768 \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--enable-auto-tool-choice \
--tool-call-parser minimax_m2 \
--reasoning-parser minimax_m2_append_think \
--trust-remote-code \
--host 0.0.0.0 \
--port 8000
mlx
土豪苹果用户必选天然是 MLX
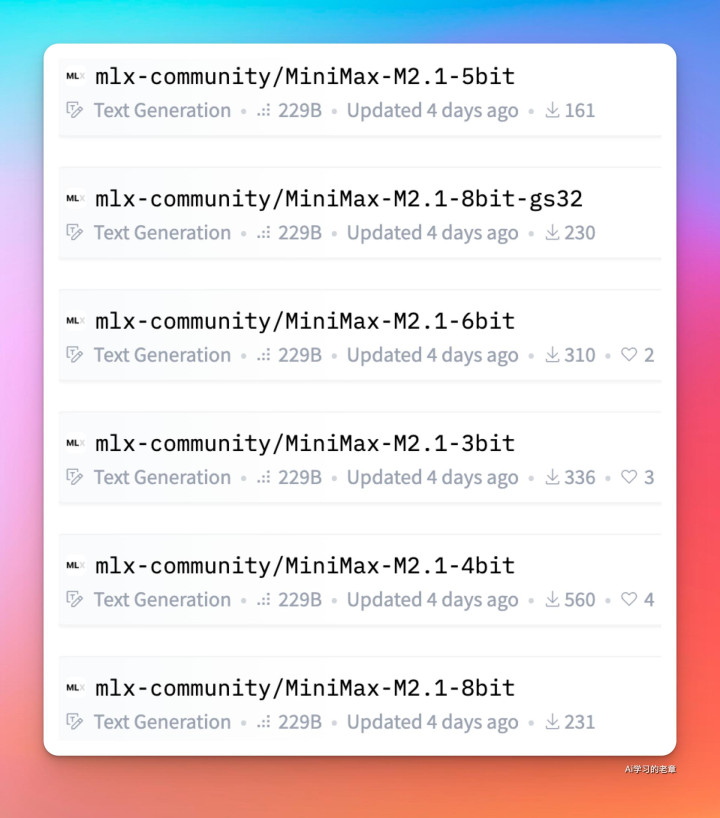
https://huggingface.co/mlx-community/models?search=m2.1
比拟受迎接的 4bit 版块,文献 129GB
启动剧本:
#装置:pip install mlx-lm
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/MiniMax-M2.1-4bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)